Stages of Scanning
Operating as a black-box web application security scanner, Acunetix 360 scans your web application like a hacker. In order to do that, Acunetix 360 crawls and attacks the target web application, web services, and web API that is available through HTTP or HTTPS. It presents vulnerabilities and issues and provides recommendations to harden your system both during and after the scan. Acunetix 360 also used its Proof of Exploit technology to actively and automatically verify detected vulnerabilities.
Acunetix 360 scans consist of four stages:
- Stage 1: Crawling
- Stage 2: Attacking
- Stage 3: Recrawling
- Stage 4: Late Confirmation
Information This article assumes you have a working knowledge of Acunetix 360. |

Stage 1: Crawling
As part of any hacking attempt, cybercriminals first conduct active and passive information gathering to fine-tune their attacks on the target web application. They check possible vulnerabilities in attack vectors or try to create anomalies in target web applications to detect weaknesses. This information gathering effort is what happens during the Crawling stage in the Acunetix 360 scanner.
- Acunetix 360, in a similar way to a web crawler in a search engine, visits every link that it detects and makes requests to all input points in detected resources, including the URLs used to reach these resources.
- It also clicks all buttons and fills out all forms to access additional pages that are only accessible once the form is submitted.
In this way, Acunetix 360 populates its Link Pool so that it can launch attacks on the target application.
What is Acunetix 360's Link Pool?
The Link Pool is the most important concept in the Crawling phase. During this phase, Acunetix 360 populates the link collection that presents attacking vectors and input lists. The scanner continues to add new links to this pool during crawling.
But, how does Acunetix 360 identify links that it will add to the link pool? Which steps does it follow?
In order to feed the link pool, Acunetix 360 follows a series of steps:
Each is explained in the section below.
Text Parser
We also provide further information on the limitations of the Text Parser.
In English, to parse means to divide (a sentence) into grammatical parts, and identify the parts and their relation to each other. Similarly, in the computer sphere, a parser takes input and builds a data structure.
The Text Parser feature in Acunetix 360 parses a web page and acquires the structure of an HTML page. Using this structure, Acunetix 360 can reach all elements. From this point, it identifies all the attributes of each element, such as href and src – source and link – to further populate the Link Pool.
Sometimes, Acunetix 360 encounters structural limitations. For example, developers can specify a part of the HTML code as comments that browsers do not compile. A user would never see these comments on a website. They would be able to see them only if they reviewed the page source.
These sections can include sensitive information or links, such as:
<!-- For test environment http://192.168.0.19:4444/test-->.
Acunetix 360 can overcome this structural limitation by parsing these sections using RegEx, enabling further information to be added to the Link Pool.
The Text Parser is enabled by default in Acunetix 360.
How to Disable the Text Parser in Acunetix 360
- From the main menu, click Policies, then New Scan Policy (or select an existing one from Scan Policies).
- From the Crawling tab, deselect the Text Parser checkbox.
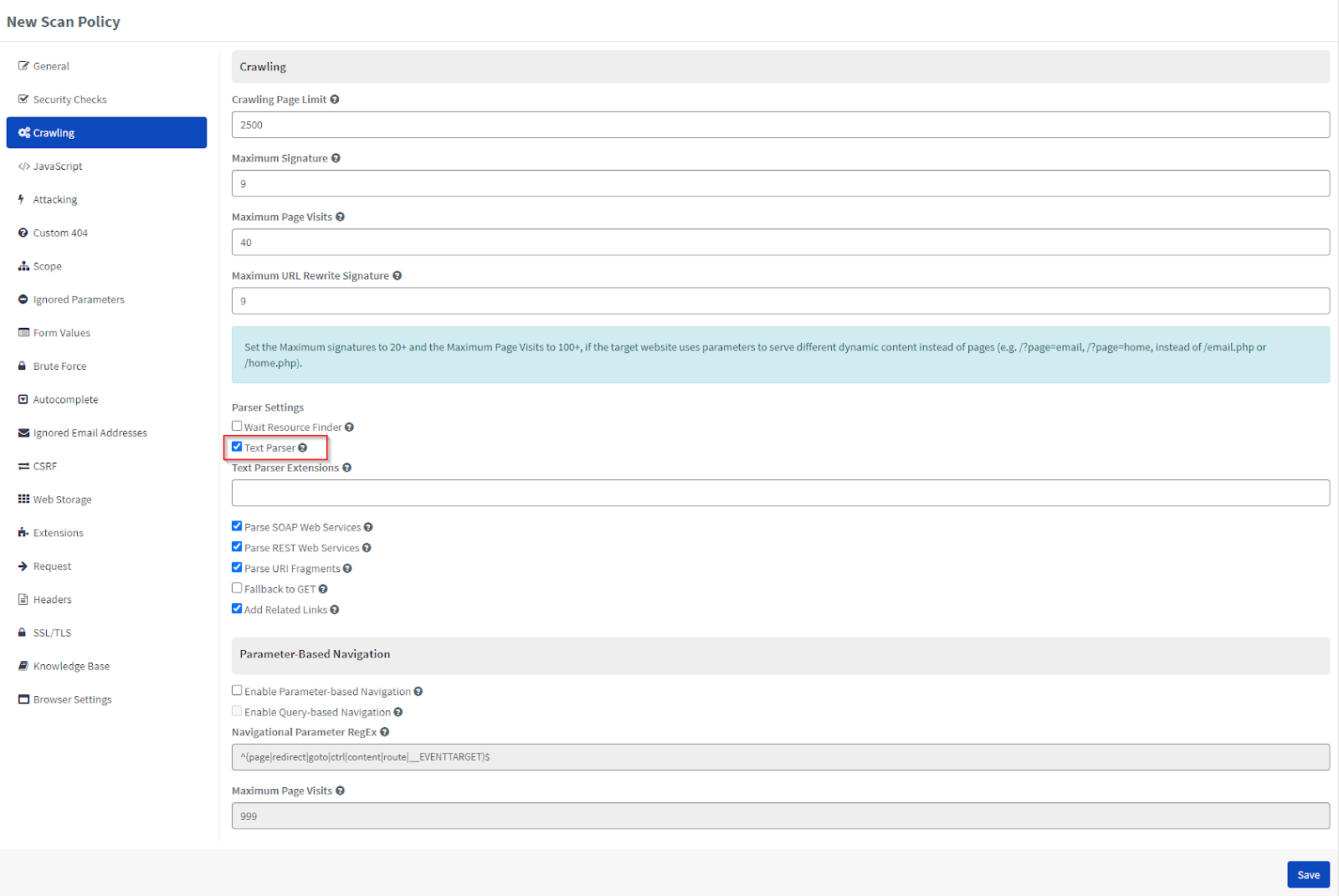
Information Please note that Acunetix 360 does not carry out text parsing in all HTTP responses. Instead, it targets those files whose extensions are specified by default in the Crawling option. From here, you can also instruct Acunetix 360 to parse extensions that are not present in the default extension list. |

Static and Dynamic DOM Parsing
In addition to text parsing, Acunetix 360 goes beyond the actions of a web crawler. It also analyzes the DOM (Document Object Model) of the website formed by browsers and identifies new input points.
For this analysis, Acunetix 360 waits for the browser to create the DOM. Using both static and dynamic parsing helps Acunetix 360 to access links to further populate the Link Pool.
- Using the Static Parsing DOM, the scanner accesses attributes containing links and elements. For example, Acunetix 360 can access the href value of all anchor elements.
- Using the Dynamic Parsing DOM, the scanner simulates user behaviors in the DOM, clicking buttons and links to trigger new events on a website. For instance, it attempts to activate the XMLHttpRequest, which is used to interact with servers, on the website.
The DOM Parser is enabled by default in Acunetix 360.
How to Disable the Analyze the JavaScript/AJAX (DOM Parser) in Acunetix 360
- From the main menu, click Policies, then New Scan Policy (or select an existing one from Scan Policies).
- From the JavaScript tab, deselect Analyze JavaScript/AJAX.
Context Relative Parsers
In addition to text and DOM parsing, instruction files are a valuable source of links for Acunetix 360.
- The sitemap.xml file is a roadmap for a website that leads a web crawler to all of your important pages.
- The robots.txt file instructs search engine bots on which pages or files can or cannot be requested from a website.
- Similarly, in the iOS development, the ASAA (App-Site Association) file acts as another source for Acunetix 360 to find links. It is a way for developers to direct iOS users to open certain parts of a website in the corresponding app instead of the browser.
These are just a few examples of files that can yield more sensitive information and links to Acunetix 360.
API Definition Files
Acunetix 360 crawls both web applications and web services. Web services are basically endpoints that expose their functionality to the world. These services can be SOAP (Simple Object Access Protocol) or REST (Representational State Transfer).
During the crawling, Acunetix 360 parses SOAP or REST API Definition files (WSDL, WADL, OpenAPI) to access new links to feed the link pool.
How to Configure the SOAP and REST Web Services Options in Acunetix 360
- From the main menu, click Scan Policies, then New Scan Policy (or select one from Scan Policies).
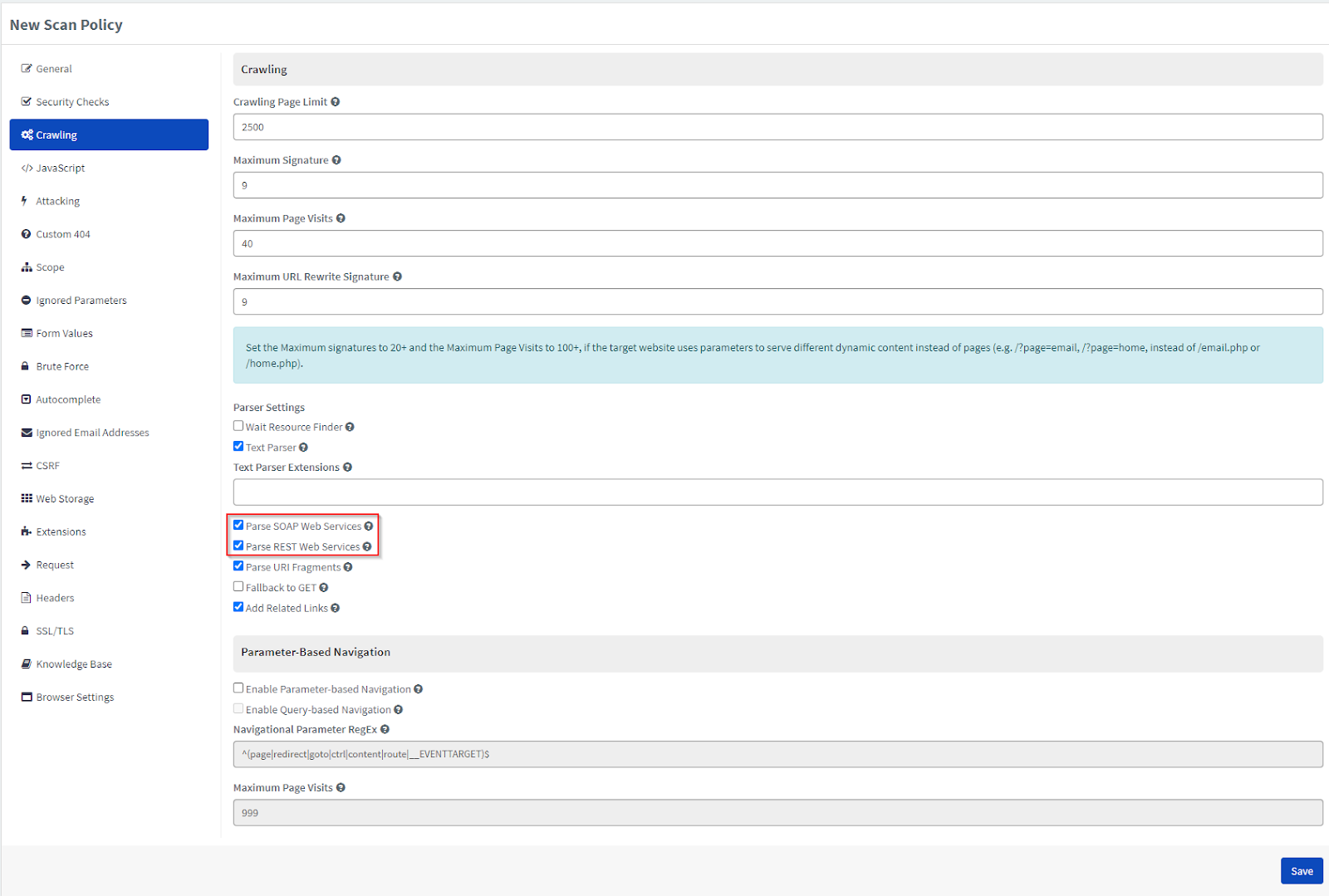
- From the Crawling tab, enable or disable the Parse SOAP Web Services and/or Parse REST Web Services checkboxes.
Extra Finders (Resource finder, Backup modifier, etc.)
In addition to text and DOM parsing, and accessing instruction files and web services, Acunetix 360 probes deeper into the target web application to access more links and identify possible vulnerable points.
Acunetix 360 checks files and folders that can lead to security risks, even when they are not linked in the web application. These files can be admin, login, or backups, for example. Using the Wordlist Entries, Acunetix 360 determines whether management, configuration, or similar files are present in web applications. The scanner uses these files to access additional links and therefore, report more vulnerabilities. For further information, see Forced Browsing.

There are at least 400 records in the Wordlist Entries. If you want Acunetix 360 not to check each of these records, you can set a limit. By default, this limit is 125, but you can amend this. This means that Acunetix 360 will check the first 125 records during the Crawling stage.
How to Configure the Resource Finder Limit in Acunetix 360
- From the main menu, click Policies, then New Scan Policy (or open one from the Scan Policies tab).
- Click the Security Checks tab, then from the Resource Finder list, select Forced Browsing.
- The Resource Finder Limit is displayed. Increase or decrease the limit as required.
Minimizing the Burden on the Web Application
Limiting the resource finder is intended to minimize the burden that the scan may place on web applications. While the methods used are designed to detect potential vulnerabilities, it's also important to avoid doing anything that might cause a live web application to crash.
To offload some of the burden from the server and the client during resource discovery, Acunetix 360 uses the HEAD method in its requests. This prevents the client from loading all the content on a web page; it displays only information found in the header section. Since the body section, which holds the main content of a webpage, is not loaded, this method reduces some of the burden on the web application and saves network bandwidth.
What if a server does not support the HEAD method?
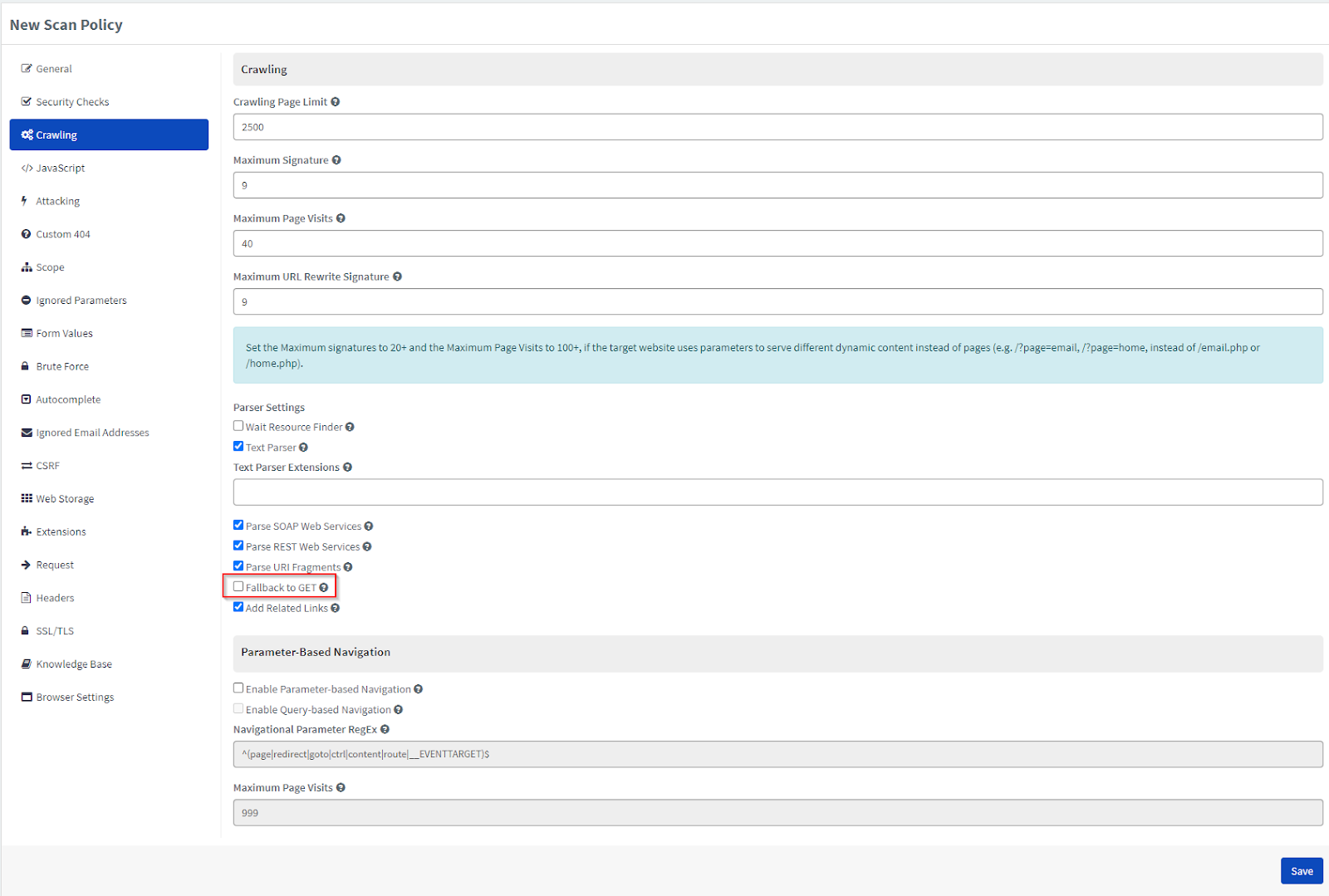
Acunetix 360 has a solution – a fallback mechanism. When enabled, it makes the same request using a GET method. By default, this option is disabled. If the target application does not support the HEAD method, you can enable this.
How to Enable the Fallback to GET Option in Acunetix 360
- From the main menu, click Policies, then New Scan Policy (or select one from the Scan Policies window).
- Click the Crawling tab.
- Enable the Fallback to GET checkbox.
In some cases, resource discovery can be crucial. Resources such as configuration files, sensitive folders, and admin panels, for example, may be vital for the security of the web application. Also, resources accessed by the Resource Finder can reveal more links.
You can instruct Acunetix 360 to start crawling from these resources before the steps mentioned above. If so, the security scanner discovers all these folders and files in the target web application. It then moves into the Crawling and Attacking stages.
This option is disabled by default.
How to Enable the Wait Resource Finder Option in Acunetix 360
- From the main menu, click Scan Policies, then New Scan Policy (or select one from Scan Policies).
- From the Crawling tab, enable the Wait Resource Finder checkbox.
Related Links
During the Crawling stage, Acunetix 360 visits other links to feed the Link Pool that it has accessed via detected URLs.
For example, if Acunetix 360 discovered www.example.com/library/classics/crime-and-punishment, it would add three new links to the link pool:
- www.example.com/library/classics/crime-and-punishment
- www.example.com/library/classics/
- www.example.com/library/.
This option is enabled by default in Acunetix 360.
How to Disable the Add Related Links Option in Acunetix 360
- From the main menu, click Scan Policies, then New Scan Policy (or select one from Scan Policies).
- From the Crawling tab, deselect the Add Related Links checkbox.
Limiting the Link Pool
Acunetix 360 has been designed so that its Crawling activities does not place an overwhelming burden on web applications, or lead to a crash, during scanning. (This is one of the reasons it uses the HEAD method, as outlined above.) In addition, you can further configure Acunetix 360 to complete the security scan in the optimum time with the highest coverage and conclusive results (by limiting the Link Pool in order to prevent unending crawls and security scans, particularly in larger websites).
By default, Acunetix 360 has a default limit of 2500 links. It simply disregards any new links beyond that. This limit is crucial for the scan duration and coverage. However, you can reconfigure this limit.
How to Configure the Crawling Page Limit in Acunetix 360
- From the main menu, click Scan Policies, then New Scan Policy (or select one from Scan Policies).
- In the Crawling Page Limit field, adjust to the required number.
Scan Scope Alternative
There is an alternative to this tactic of limiting the Crawling Page Limit in the Scan Policy. You can simply configure which links will be added to the link pool using the Scan Scope. This allows you to define which parts of the target web application should be crawled.
For further information, see Scan Scope for Acunetix 360.
Signatures
In a bid to limit the crawling and perform a better scan, Acunetix 360 creates a signature that contains a URL and parameter value in the request and method, which defines the request and makes it unique. Unless otherwise instructed, Acunetix 360 collects nine examples of a signature during the Crawling stage. In this way, Acunetix 360 has access to all possible variations for the resource.
www.example.com/contact.php?id=1
www.example.com/contact.php?id=2
www.example.com/contact.php?id=3
www.example.com/contact.php?id=4
www.example.com/contact.php?id=5
www.example.com/contact.php?id=6
www.example.com/contact.php?id=7
www.example.com/contact.php?id=8
www.example.com/contact.php?id=9
Similarly, Acunetix 360 caps visits to a single URL at 40 times, even if it has found a different parameter. You can configure the Maximum Page Visit setting in the Crawling tab of the Scan Policy.
In general, if you want to know which links Acunetix 360 has detected and added to the Link Pool, you can export and examine a Crawled URLs List. Here is a sample report.
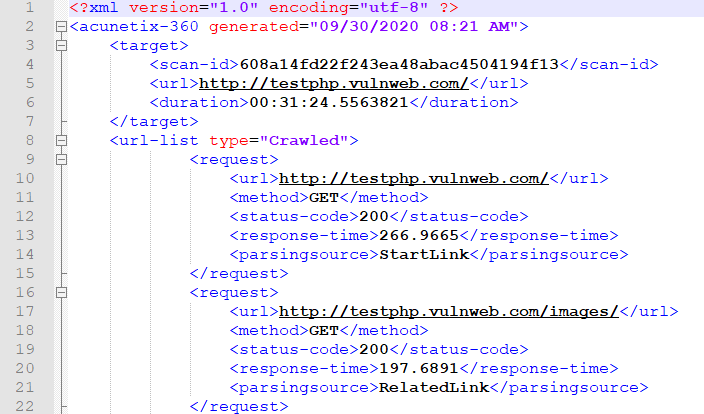
Stage 2: Attacking
This is the second stage of Acunetix 360's scanning process.
There are three parts to the Attacking stage:
- Detection
- Confirmation
- Proof Generation
Detection
In the first part of the Attacking stage, Acunetix 360 sends payloads appropriate for input points in the target web application. This is called Detection.
For instance, Acunetix 360 tries Reflected XSS payloads to all input points and attempts to detect a pattern in the expected output. If Acunetix 360 finds this pattern, this is the first indicator of a vulnerability. Behavioural patterns, as well as textual output, may signal a vulnerability.
Confirmation
Following a first sign in the output or behavioral pattern, detected in the Detection part of the Attacking stage, Acunetix 360 conducts follow-on activities to confirm that the vulnerability is not a false positive. This is called Confirmation.
In the example of Reflected XSS, when Acunetix 360 identifies that the XSS payload was reflected without encoding in line with the context (Detection), the scanner uses an XSS payload to execute script codes to confirm the vulnerability (Confirmation). Acunetix 360 carries out this in a read-only method without causing harm to the target web application.
Similarly, in command execution and code evaluation vulnerabilities, the security scanner exploits and confirms vulnerability (without causing damage to the target web application) using various methods such as string concatenation and arithmetic calculation. When it receives an expected response, it reports this vulnerability as Confirmed, removing the need to manually verify its existence.
Proof Generation
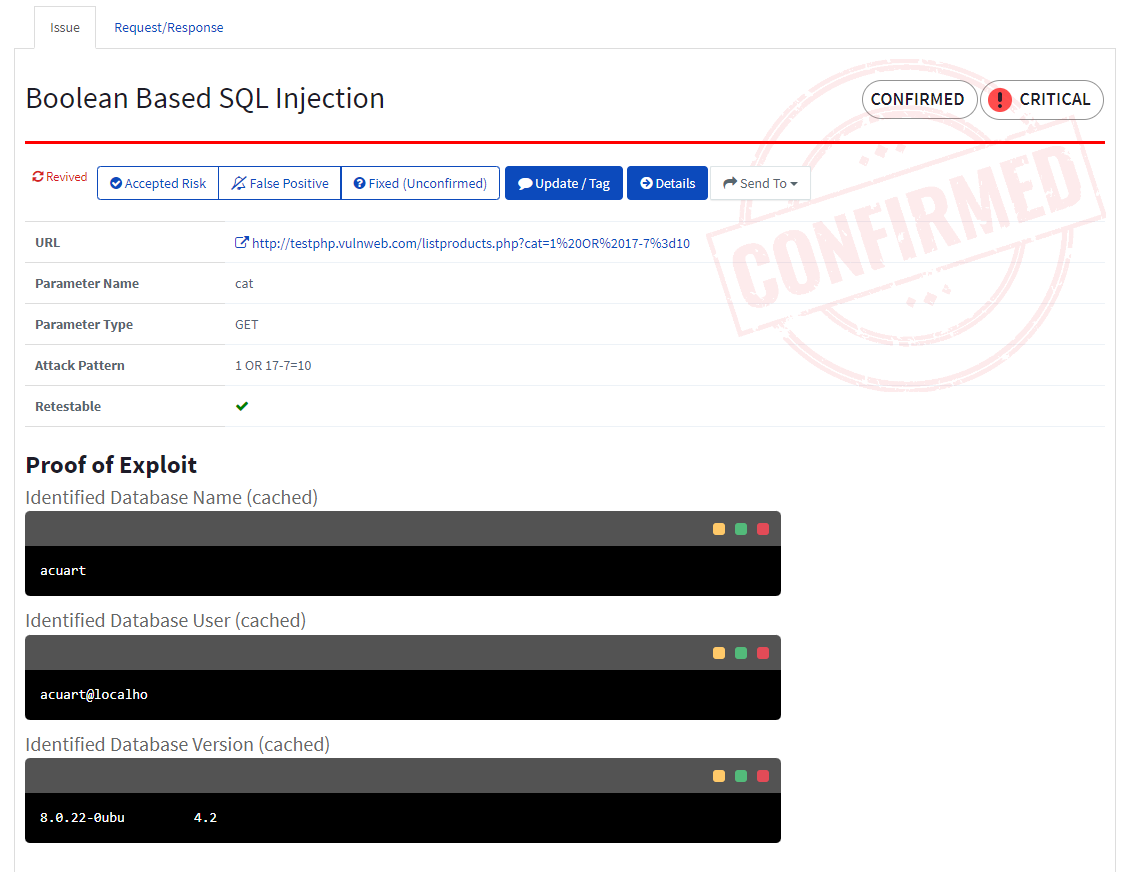
In addition to the Detection and Confirmation parts of the Attacking stage, Acunetix 360 has the unique ability to illustrate the proof of exploit for a vulnerability as a part of its Proof of Exploit technology. Acunetix 360 reports display not only the vulnerability and its confirmation, but a proof for the vulnerability following its exploitation.
Netparker can detect and demonstrate proof for a long list of vulnerabilities.
Here is a sample Proof of Exploit.
Crawling and Attacking at the Same Time
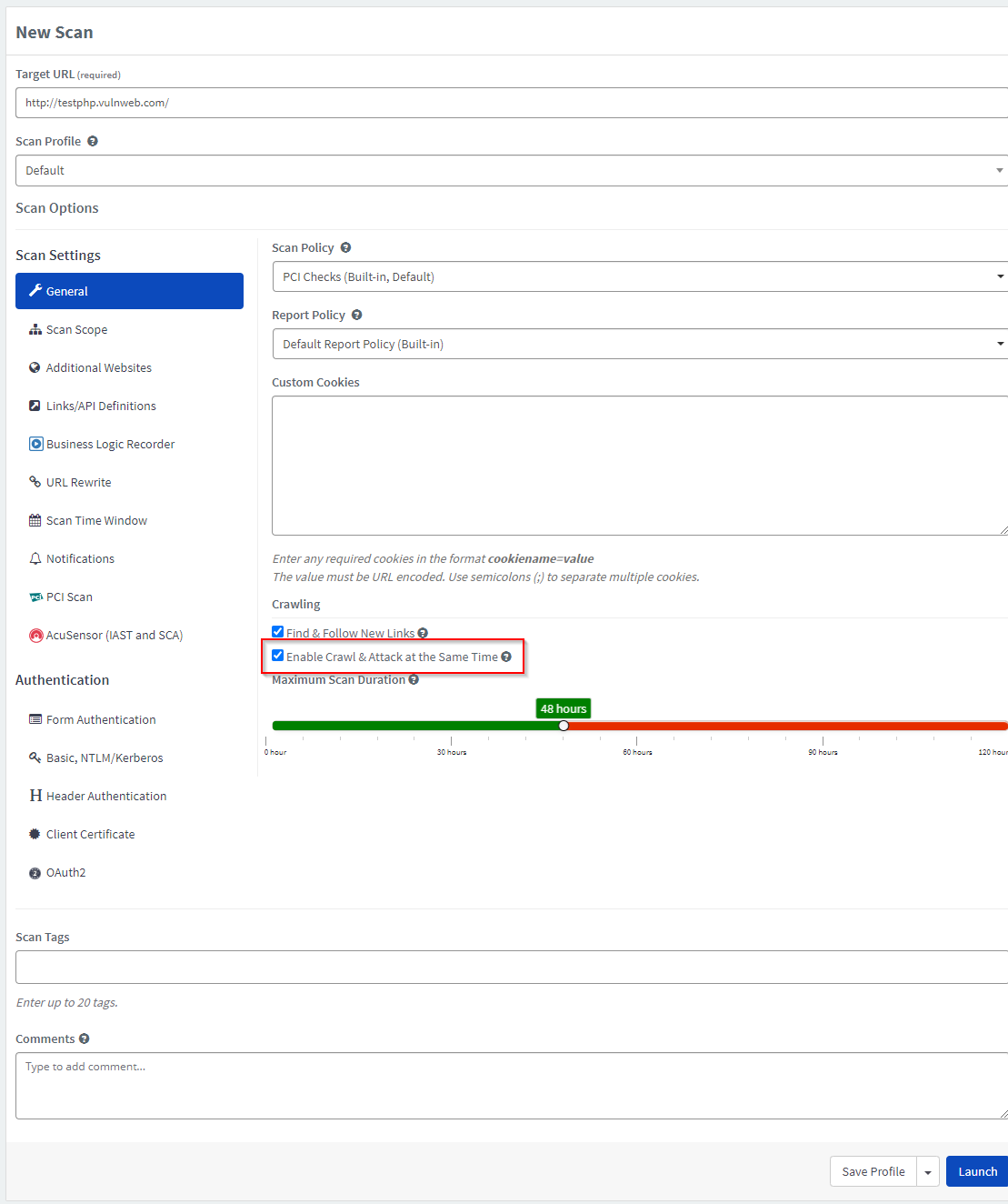
Though we have described the process in two distinct stages, note that Acunetix 360 can crawl and attack web applications at the same time. By default, Acunetix 360 continues crawling and adding links to the Link Pool while attacking these links.
You can disable this setting.
How to Disable the Enable Crawling and Attacking at the Same Time Setting in Acunetix 360
- From the main menu, click Scans, then New Scan Policy (or select an existing one from Scan Policies).
- From the General tab, deselect Enable Crawl and Attack at the Same Time.
In general, if you want to know which links Acunetix 360 has attacked, you can export and examine a Scanned URLs List. Here is a sample report.
Stage 3 and 4: Recrawling & Late Confirmation
These are the combined third and fourth stages of Acunetix 360's scanning process.
By this point in the process, Acunetix 360 has crawled the target web application and attacked detected links.
In the Recrawling stage:
- The security scanner recrawls the links present in the Link Pool, because the Attacking stage may have uncovered new links. Acunetix 360 may report new vulnerabilities in the Recrawling stage.
- Also, vulnerabilities such as Stored XSS and second order issues can be identified when the security scanner revisits the webpage to examine the output. These vulnerabilities cannot be identified the first time around – when the attack payload is sent and response received. The scanner has to visit the web page again to examine the response. Acunetix 360 revisits these web pages to identify further vulnerabilities.
In the Confirmation stage:
- Acunetix 360 can delay the confirmation of some vulnerabilities to avoid affecting the whole scan. For example, time-based vulnerabilities, such as Blind SQL Injection, rely on the database pausing for a specified amount of time (e.g. 10 seconds). Exploiting such vulnerabilities may affect other security checks during the scan. So, Acunetix 360 delays the confirmation to the Recrawling and Late Confirmation stage.
- Similarly, Acunetix 360 confirms out-of-band vulnerabilities in this stage using Hawk, the DNS responder (see How Hawk Finds Vulnerabilities).
Knowing how each stage works can help you fine-tune Acunetix 360 scanning options in order to complete a scan in the optimum time with the widest possible coverage and the most accurate results.
In addition, it is also important to know the target web application in detail to better configure the scan. Acunetix 360 also helps you better understand your web application, so that you can set the Scan Policy and Scan Profile. Based on these configurations, the scanner acquires information on the technology stack of the target web application and reports that information. It also acquires the behavioral characteristics of the web application and reports them in the Knowledge Base Nodes.